
ES 模块标准化了将近 10 年,好消息是现在各大主流浏览器厂商已经原生支持 ES 模块,同时 NodeJS 对 ES 模块原生支持也在完善中。
许多前端开发者都知道 ES 模块一直存在争议。但很少有人真正了解 ES 模块的工作原理。让我们来看看 ES 模块解决了什么问题,以及它们与其他模块系统中的模块有何不同。
ES 模块解决了什么问题
仔细想想,我们平时的编码过程就是管理变量的过程,为变量赋值,为变量添加数字,将两个变量组合在一起并将它们放入另一个变量中等等。
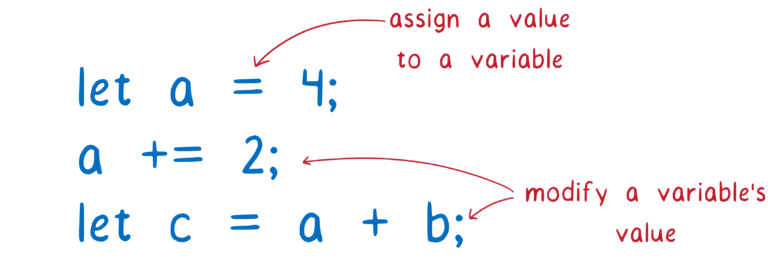
因为我们大部分代码都只是关于更改变量,所以如何组织这些变量将对我们的编码能力以及维护代码的能力产生重大影响。
借助于 JavaScript 的作用域,我们可以一次只管理几个变量,极大的降低了编写和维护代码的难度。但是由于作用域的限制,函数无法访问其他函数中定义的变量。如果我们需要跨作用域共享一些变量,将会非常麻烦。
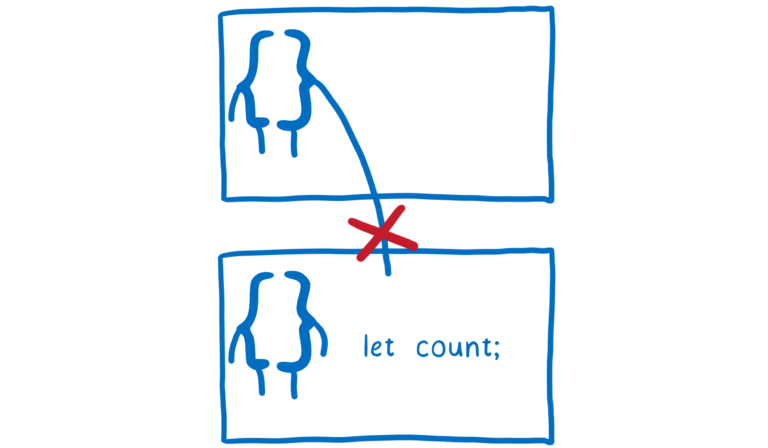
如果我们想在作用域之外共享变量的话,通常只能将变量放在更上层的作用域里。比如,放在全局作用域内。就像在 jQuery 时代,在加载任何 jQuery 插件之前,我们必须确保 jQuery 在全局作用域内。
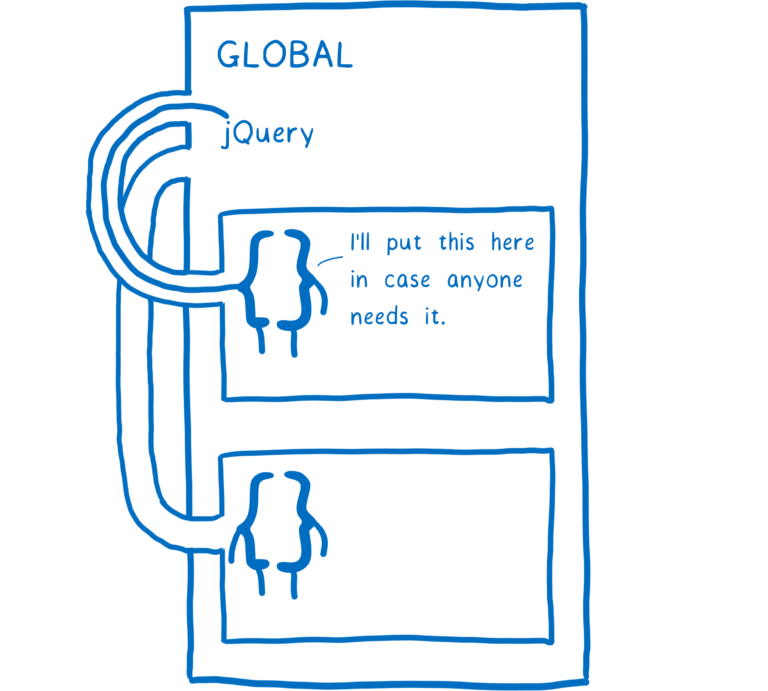
虽然这种方式可以很好的工作,但是也有很多问题。比如,所有 JS 脚本都需要按正确的顺序排列,同时我们还要确保没有人把这个顺序弄乱。一旦顺序出错,那么在运行过程中,我们的应用程序就会抛出错误。
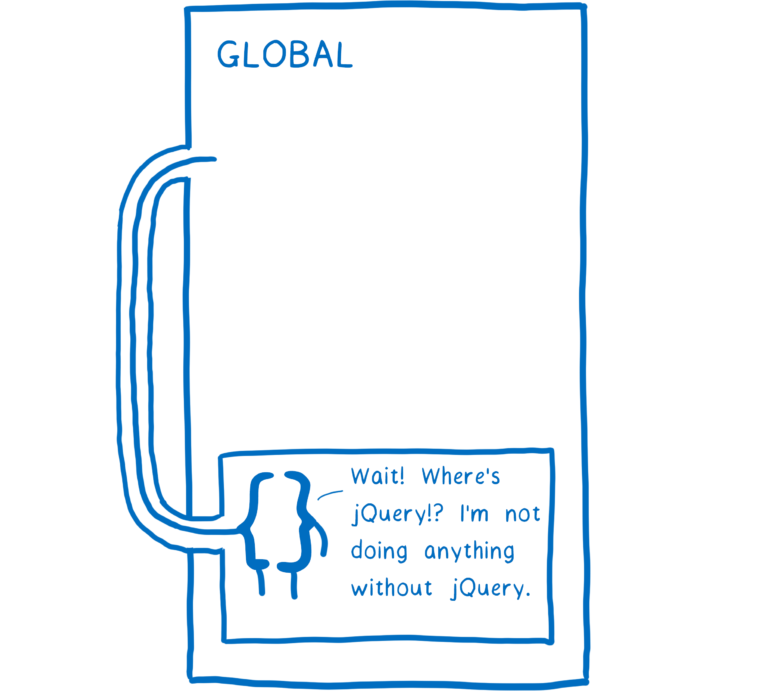
长此以往,代码变得越来越难以维护。因为不同代码之间的依赖关系是隐式的,删除旧代码或脚本标签的后果变得不可预知。任何函数都可以获取全局作用域上的任何东西,所以我们也不知道哪些函数依赖于哪些脚本。
同时,因为这些变量在全局作用域内,理论上任何一段代码都可以更改这些变量。恶意代码可以故意更改变量,导致代码执行预期之外的事情。非恶意代码也可能意外破坏变量导致程序出错。
模块如何解决这个问题
使用模块,我们可以将有意义的变量和函数组合在一起。这些变量和函数都处于同一个模块作用域中,函数之间可以共享这些变量。同时,模块还可以与其他模块共享变量或者函数,只需要将这些可以共享的函数或者变量导出即可。
当一个变量或者函数可以被模块外访问时,我们称之为导出了这个变量或函数。当一个变量或函数被导出后,其他模块就可以使用这个变量或函数。
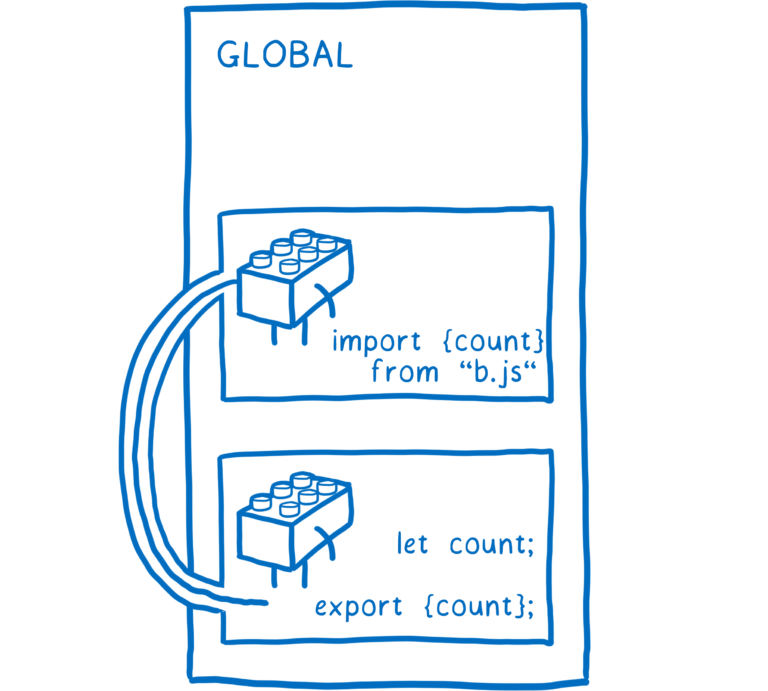
这是一个明确依赖的关系,所以我们可以判断出如果删除另一个模块,哪些模块会出错。
当我们能够在模块之间导出和导入变量之后,我们就可以更轻松地将代码分解为可以相互独立工作的小块。然后我们可以重新组合这些块,来创建不同类型的应用程序。
由于模块非常有用,在 ES 模块之前就已经有模块系统存在了。CommonJS (CJS) 是 NodeJS 正在使用的模块加载规范。
ES 模块是如何工作的
当我们使用模块进行开发时,我们会构建一个依赖关系图。不同依赖项之间的连接来自我们使用的任何 import 语句。
浏览器或 NodeJS 通过这些 import 语句来感知需要加载哪些代码。通过从程序的入口文件开始,浏览器或者 NodeJS 会跟随任何 import 语句来查找其余的代码。
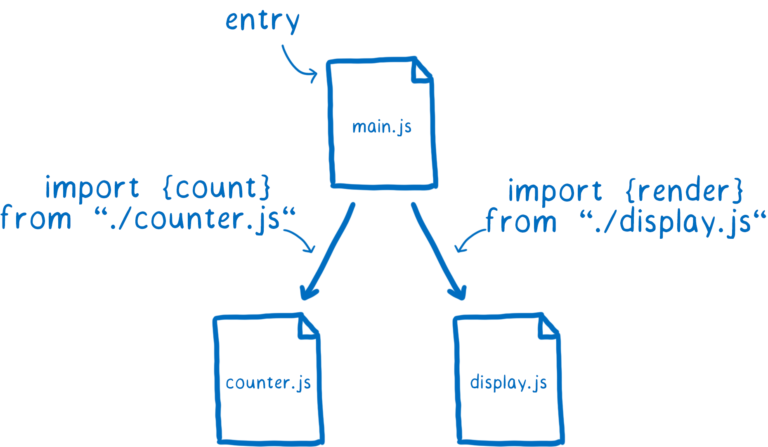
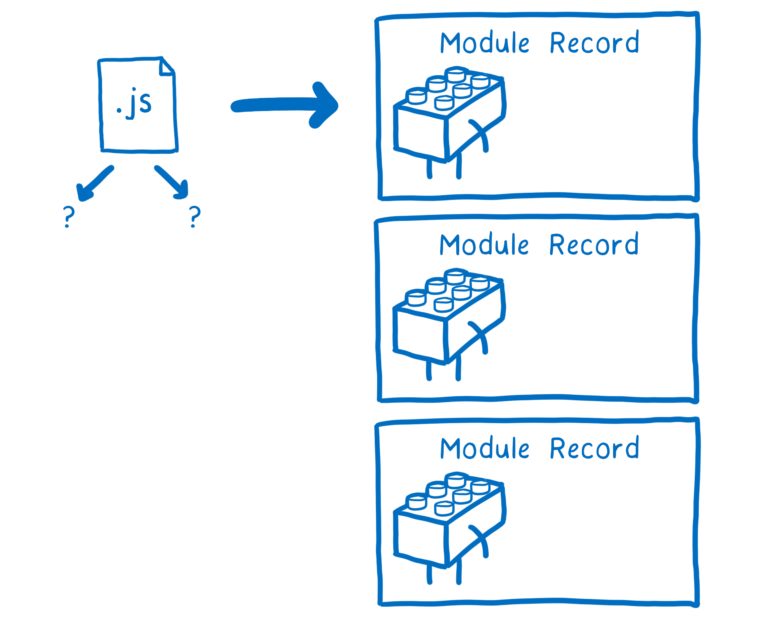
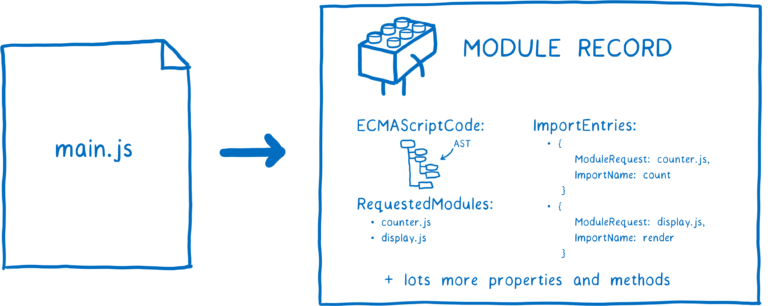
浏览器或者 NodeJS 解析所有这些文件,将它们转换为一定的数据结构,这个数据结构被称为模块记录(module record)。
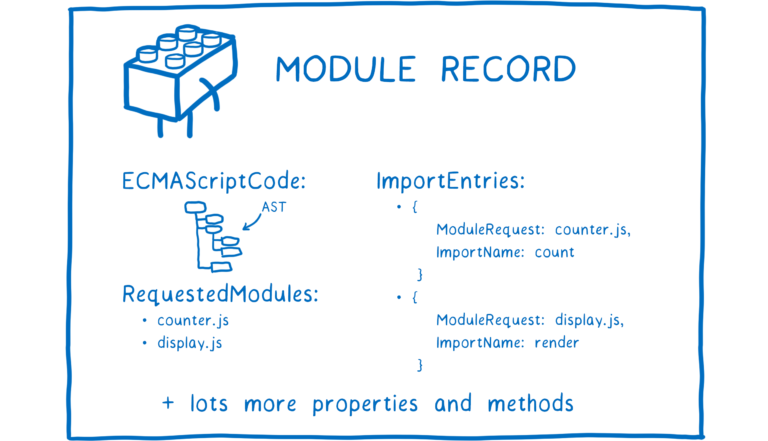
之后,模块记录被转化成模块实例。一个模块实例包含两部分:代码和状态。
代码是一组指令,就像一个指导说明。我们不能使用代码本身做任何事情,我们需要借助于状态来使用这些指令。状态是变量在任何时间点的实际值,存储在内存中。
因此,模块实例包含代码(一组指令)和状态(变量的值)。
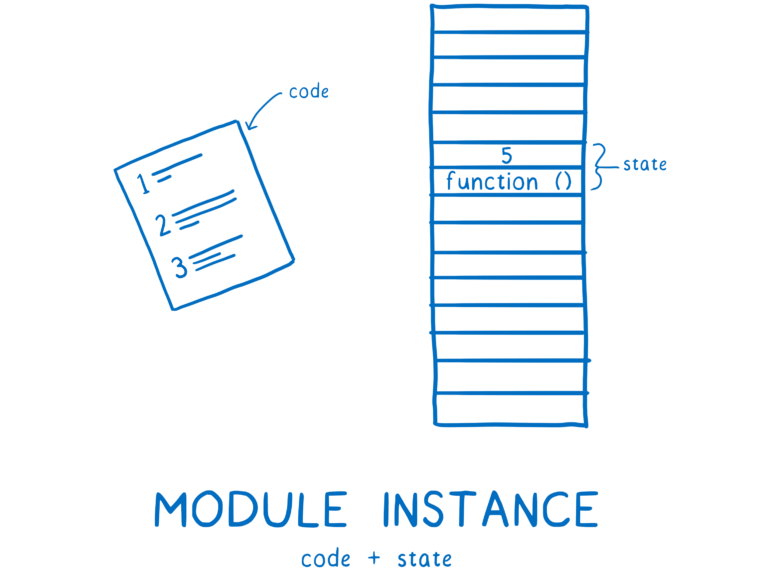
程序运行的时候需要的是每个模块的模块实例。模块加载的过程就是从这个入口点文件到拥有一个完整的模块实例图的过程。
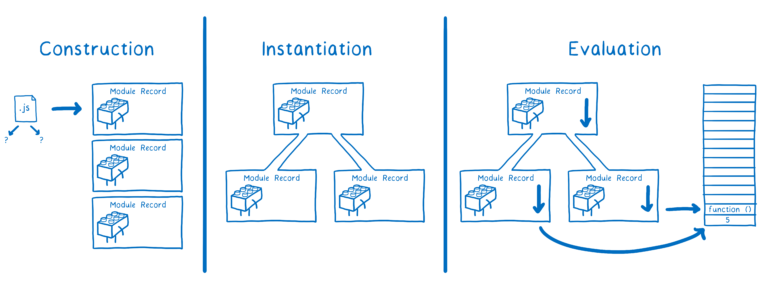
对于 ES 模块来说,通常分为三步:
- 构建过程(Construction) -- 查找、下载和解析所有的模块文件,生成模块记录。
- 初始化(Instantiation) -- 为模块导出的变量分配内存(但不求值)。然后将导入和导出都指向这些内存地址,这称为链接。
- 求值(Evaluation) -- 运行代码,将变量值填充到内存中去。
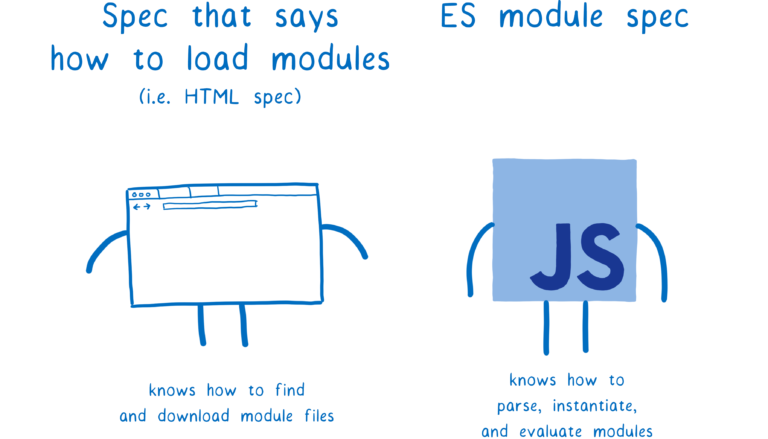
在 ES 模块规范open in new window 中只定义了如何构建模块记录,以及如何初始化和对模块求值,但是没有定义如何加载这些模块。
在浏览器中,如何加载模块定义在 HTML 规范open in new window中。
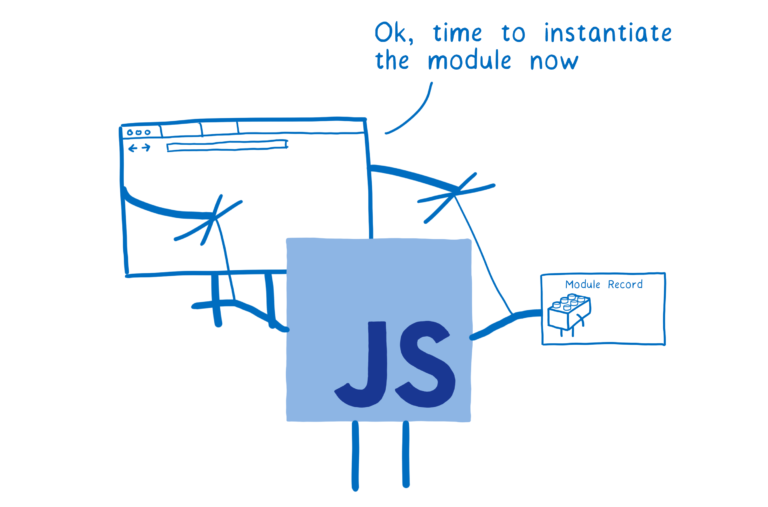
同时,浏览器还控制了如何实例化模块。通过调用 ES 模块的 ParseModule、Module.Instantiate 和 Module.Evaluate 等方法,浏览器像操作木偶一样操作 JS 引擎来实例化模块。
现在我们来看看模块实例化的每一步发生了什么。
构建过程(construction)
每个模块在构建过程都会经历如下三步:
- 确定在哪里可以获取模块(module resolution)
- 获取模块(从网络上下载或者从文件读取)
- 解析文件,将其转换成模块记录
查找并获取模块
浏览器会负责查找并下载文件。我们通过 script 标签来告诉浏览器入口文件。
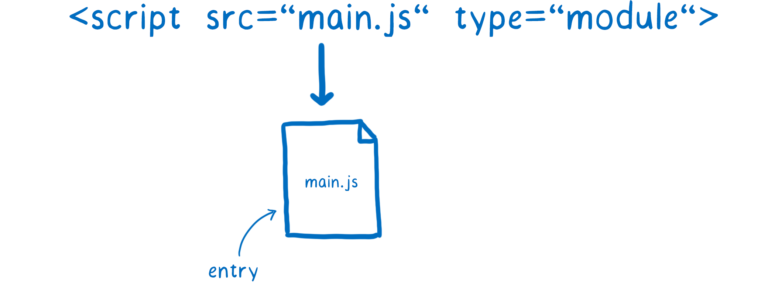
之后浏览器会根据导入语句来加载其他模块。

值得说明的是,导入语句后方的那段被称为模块说明符(module specifier)。不同平台对于模块说明符的处理不同。比如浏览器和 NodeJS 就存在差异。每个平台都会有一套模块解析算法(module resolution algorithm)来加载模块。
在浏览器中,加载模块是异步的。因为浏览器通过 URL 来查找并下载模块。假如浏览器通过同步的方式来加载模块,那么要解析模块间的依赖关系就需要顺序下载模块并执行代码才能实现,这将会非常耗时,同时在这个过程中浏览器不能做任何事情。
我们知道,CPU 时间和下载的网络耗时差别是非常大的。
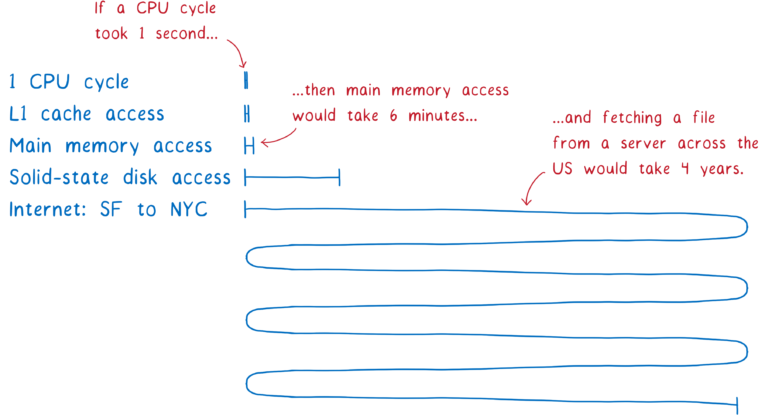
因此,同步加载模块会让我们的应用非常的慢,体验很差。因此,ES 模块的实例化过程被分成了三个阶段。将模块的构建(construction)过程独立出来以后,浏览器可以免于执行代码就能获取模块间的依赖关系。
前面说到 NodeJS 使用 CommonJS 规范来加载模块。CommonJS 模块是同步加载的。因此从文件系统读取文件比网络下载要快的多,NodeJS 完全可以在读取完文件以后直接初始化和对模块求值。因此,在 NodeJS 中,模块在其依赖的所有其他模块都完成实例化之后才会返回。
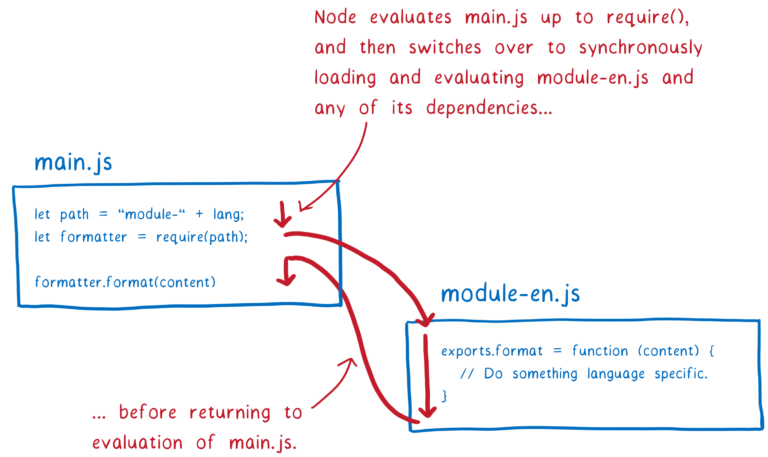
正因为 CommonJS 的这个特点,在 NodeJS 中,模块说明符(module specifier)中可以使用变量。ES 模块中不可以。

但是有时候我们确实需要动态改变模块路径,在 ES 模块中,我们可以通过动态导入open in new window的方式来实现,使用 import() 函数。
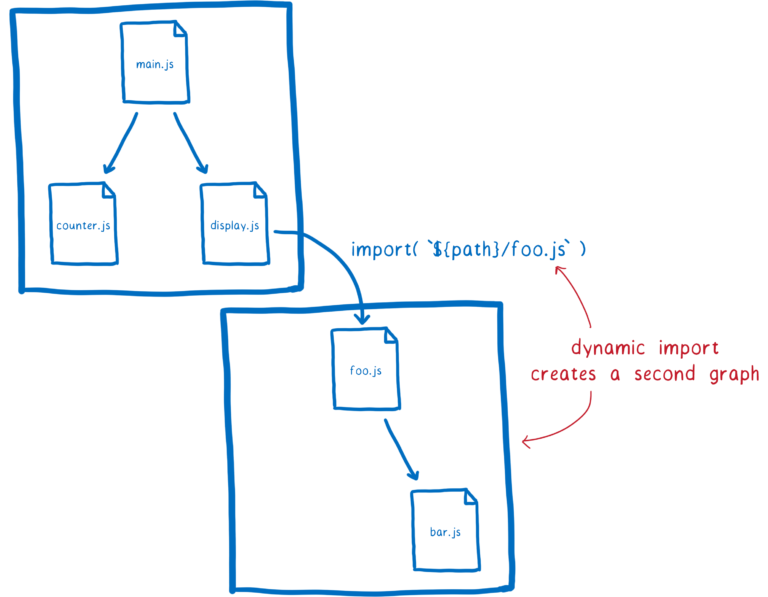
使用 import() 函数导入的模块会生成一张子模块图,这个子模块图的处理将会与当前模块图的处理隔离开。
有一点要注意,所有的模块,在任何一个阶段都只有一个实例。浏览器会缓存模块实例,这样可以避免当一个模块被多个模块依赖的时候被下载和解析多次。
浏览器使用模块缓存(module-mapopen in new window)来存储这些模块实例。每一个顶级作用域都有各自独立的模块缓存。
当浏览器解析一个模块的时候,它会把这个模块放到模块缓存中,标记模块状态为加载中(fetching)。之后浏览器会发起请求下载这个文件。
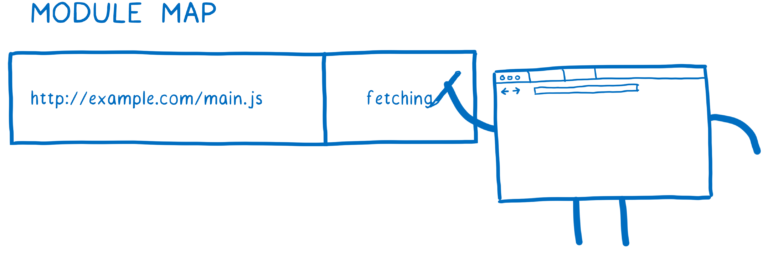
如果其他模块也依赖了这个模块,浏览器会检查模块缓存,如果发现缓存中已经有了这个模块的记录,即时还是加载中,浏览器也不会再重复处理这个模块了。
解析模块(parsing)
当浏览器获取到模块文件以后,就可以解析成模块记录。模块记录帮助浏览器识别模块中的不同部分分别是什么。
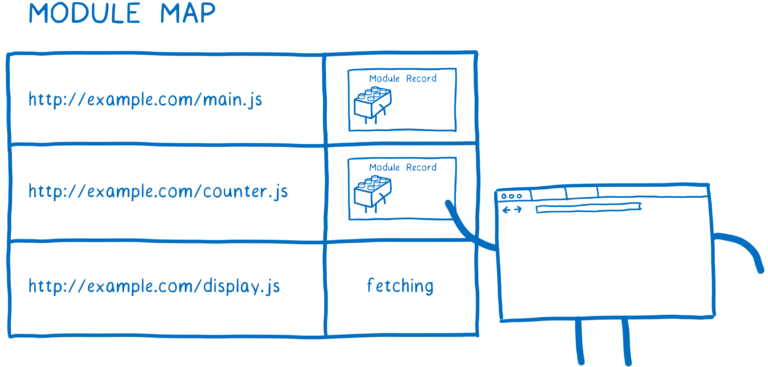
一旦模块记录生成以后,浏览器就会将其放到模块缓存中,之后在任何地方引用这个模块,浏览器可以直接从缓存中取出这个模块。
默认情况下,模块被浏览器按照严格模式("use strict")进行解析,同时顶层的 await 是保留的,顶层this 的值是 undefinded。
当然也有其他的解析方式。不同的解析方式成为解析目标(parse goal)。同一个文件使用不同的解析目标进行解析,得到的结果不同。在浏览器中,我们通过给 script 标签添加 type="module" 属性来告诉浏览器要按照模块来解析文件,在 NodeJS 中我们通过 .mjs 后缀的方式来指明这是一个模块。
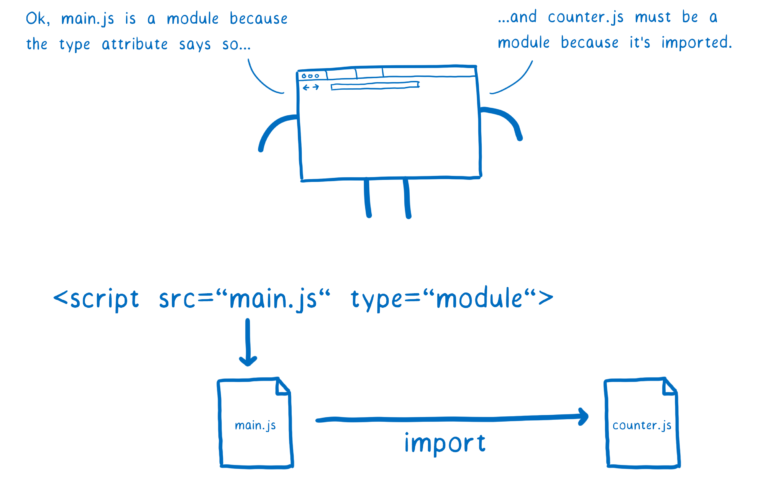
当浏览器从入口文件开始解析完所有的模块以后,我们就得到了一组模块记录。
初始化(Instantiation)
一个模块实例包含代码和状态,实例化的过程就是往内存中写入状态的过程。
首先,JS 引擎会创建一个模块环境记录(module environment record)。这个模块环境记录负责管理模块记录中的变量。然后它会在内存中为所有导出的变量分配内存地址。模块环境记录将跟踪内存中的地址和每个导出变量间的关联关系。
分配好的内存地址并不会立即被填入值,填值要等到求值(evaluation)阶段。
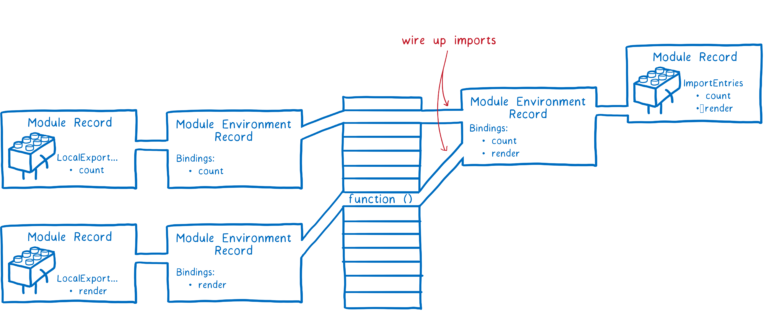
在初始化模块图的过程中,JS 引擎会通过深度优先后序遍历的方式,先处理一个模块及其依赖模块的导出,再处理导入。也就是说,JS 引擎会先找到模块依赖的模块中最末端没有任何依赖的模块,处理导出,然后逐层返回处理导出,最后处理入口模块的导出。之后,同样的方法处理导入。
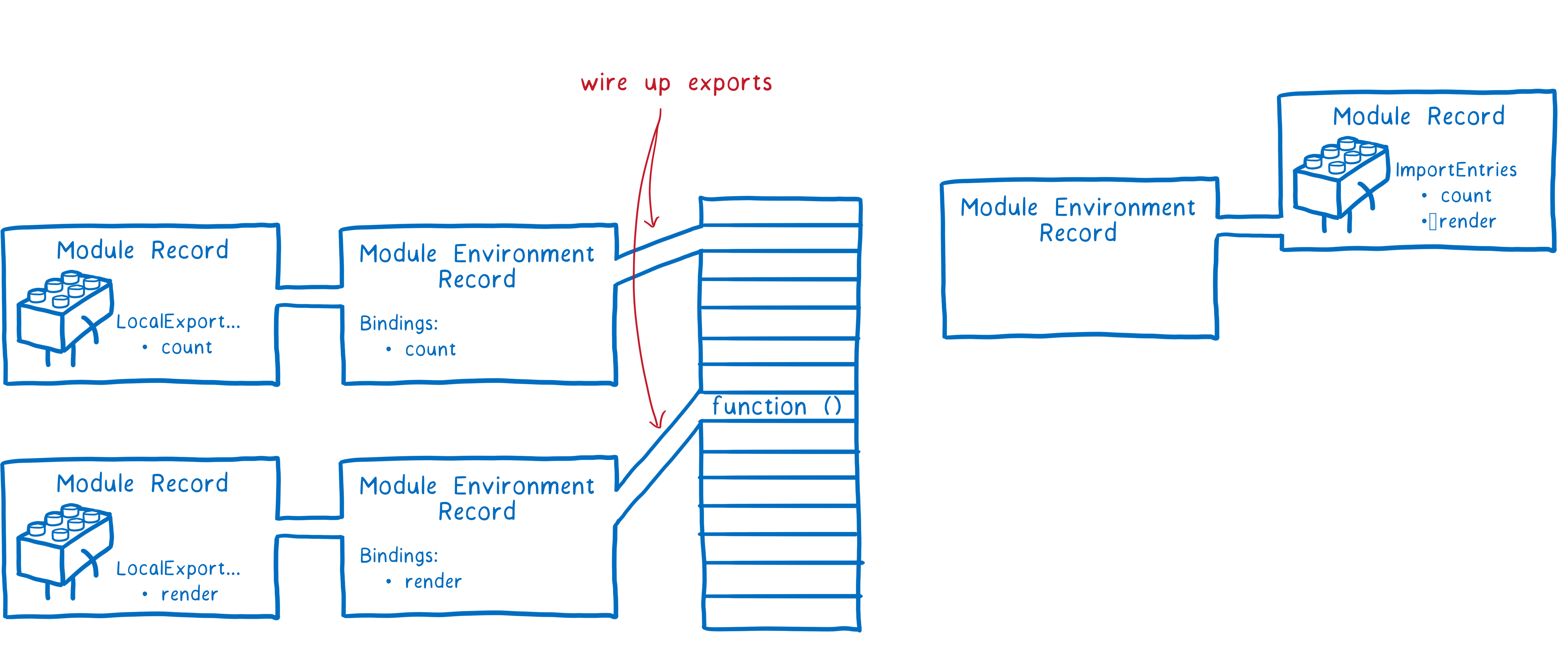
注意,导入和导出的变量在内存中指向同一个地址。先处理导出的优点是可以让导入导出一一对应。
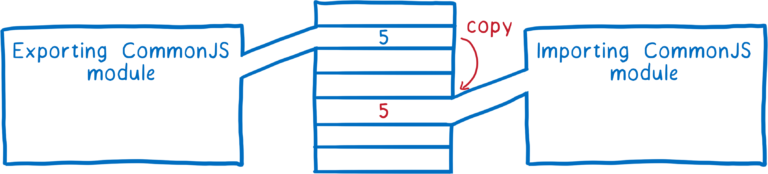
这一点与 CommonJS 不同。CommonJS 的导出是一份完全的拷贝。也就是说,如果导出的变量是一个数值,那么导出的变量是模块内变量值得拷贝。后续这两个变量之间没有任何关系。
与 CommonJS 相反,ES 模块使用实时绑定(live binding),导出的变量和导入的变量在内存中使用同一个地址,但是导入的变量不能修改变量值。
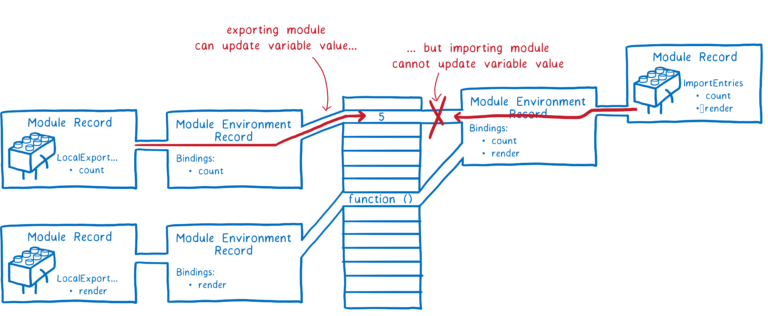
之所以使用实时绑定,是因为这样可以在不执行任何代码的情况下就能将所有模块关联起来,当处理模块间的循环引用的时候将会非常有用。
求值(Evaluation)
当浏览器开始运行代码时,会从顶层代码开始运行,及函数外的代码。

但是,执行代码必可避免的会有副作用产生。比如有些代码会向服务端发起请求。因此,同一段代码运行多次可能有不同的结果。
因此,我们需要借助于模块缓存,使得每次解析到相同模块的时候,都是引用的同一个缓存记录,从而保证每个模块的代码只执行一次。
前面说到循环依赖的问题。通常一个循环依赖会很深,即产生循环依赖的两个模块之间会有多个模块。简单起见,我们举个两个直接相互依赖的模块做例子。
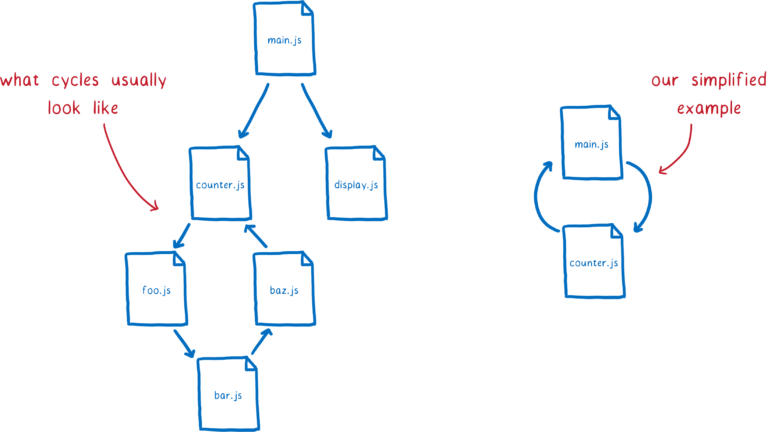
我们来看看 CommonJS 是如何处理的。
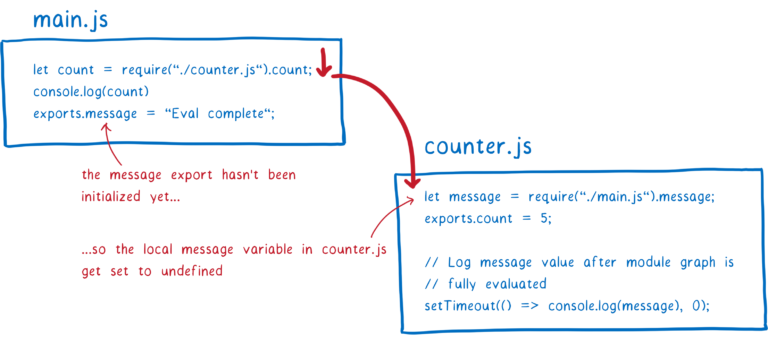
首先,JS 引擎会解析 require 语句,接着解析 Counter 模块。Counter 模块此时会尝试获取 message 的值。因为 Main 模块还没有求值,此时 message 的值是 undefined。JS 引擎会在内存中为这个变量分配内存,然后将值置为 undefined。

之后,JS 引擎执行完 Counter 模块的顶层代码,恢复执行 Main 模块的顶层代码。为了检验 Counter 是否拿到了正确的 message 的值,我们在代码中加了一个 setTimeout。
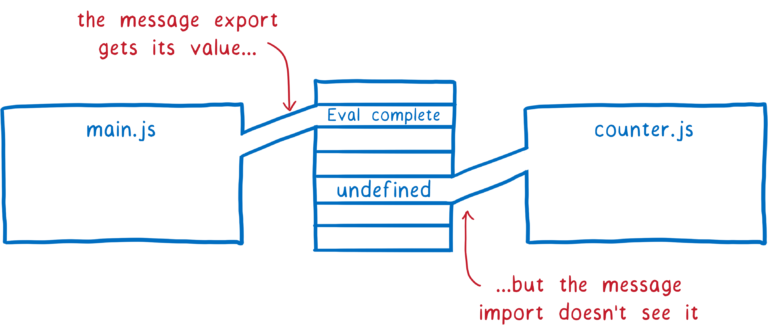
在对 Main 模块进行求值的时候,message 得到了值,写入内存。但是因为两个模块的导入导出之间没有建立连接,Counter 模块中的 message 还是 undefined。
ES 模块的实时绑定机制就可以有效解决这个问题。
 关注微信公众号,获取最新推送~
关注微信公众号,获取最新推送~
 加微信,深入交流~
加微信,深入交流~