
本文主要探讨在应用开发过程中,页面组件的开发原则。这里说的页面组件,是一个泛指,不仅仅表示一般的组件含义,也可以理解为页面的区块等。
清晰的组件结构
清晰的组件结构这条原则,更像是一种开发方法。
在页面开发之初,我们就应该先将页面的结构确定,类似于线框图open in new window,并通过代码的方式确定下来。
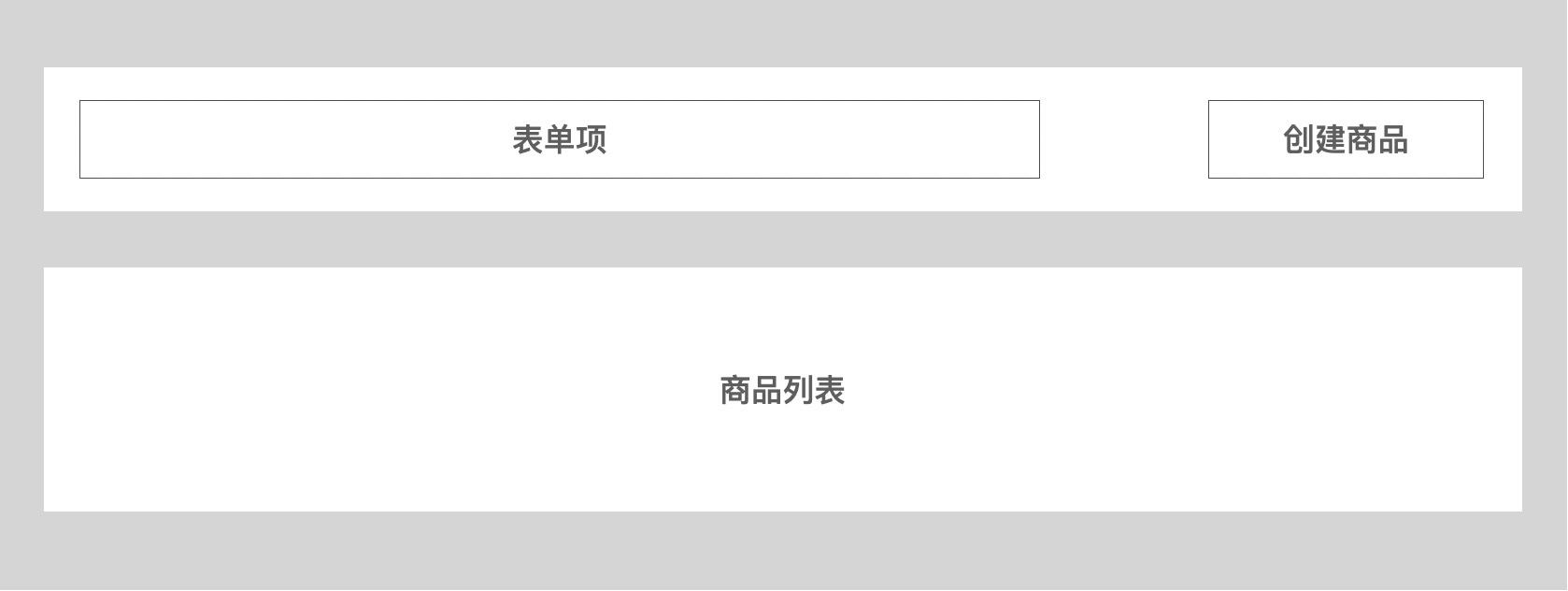
上面是一个简单的商品列表页的线框图,顶部是一个过滤表单,下面是表格。那我们就需要在确定两个大的组件,表格和过滤表单。
划分好页面区块以后,我们使用同样的方法,在区块内划分小的区块,直至最终的组件。
比如上面的例子,确定好区块以后的代码结构应该是这样的:
-- list-page
-- index.tsx
-- filter-form.tsx
-- goods-list.tsx
2
3
4
在
index.tsx中将页面区块组装成页面。
通过这种方法,我们可以快速的理清组件之间的关系,为页面状态数据设计提供一些帮助。同时,组件设计落到代码目录结构中以后,我们可以通过代码目录反推页面结构,清晰明了。
通常,我们一般习惯将所有组件都一股脑儿放到一个 components 目录中。这种做法太过粗放,组件多了以后,非常混乱,无法知道每个组件的具体用途,也不知道组件在哪个地方使用。
通过上面的方法,我们把组件放到页面代码目录中,只将通用的,没有业务含义的组件放到顶层 components 目录中。模块目录内,我们同样按照功能和用途划分目录。这样的话,顶层的 components 更具有公共组件的含义,同时,每个模块的代码是内聚的,我们可以方便的了解这个模块的全部功能。
单一数据源
单一数据源,更具体一点的说法是,凡是可以由某一个数据推导出来的数据,都应该通过推导的方式来获取,不应该另行存储。数据应该是成链路的,而且只能有一个源头。
在 React 技术栈中,单一数据源已经是基本常识了,但是很多同学受 Redux 的影响,仅仅将其理解为将应用所有数据状态都放在顶层的 state 中,通过 action 来触发状态更新。
其实不然,单一数据源有着更广泛的含义。对于组件的外部数据,组件内不应再进行存储,而是始终使用外部传递进来的数据。对于组件自身数据,如果数据之间有依赖关系,那么依赖方就尽量由被依赖方推导出来。比如数据 B 依赖数据 A,那么数据 B 应该由数据 A 推导出来,而不是更新完数据 A 后再更新数据 B。
为什么要坚持单一数据源呢?
使用过 Angular 的同学应该都有这样的体验,当项目规模越来越大,应用数据之间依赖关系越来越复杂。一个数据更新会触发其他数据更新,反方向的数据更新也同样存在。这样的话,当出现问题的时候,就很难快速的找到问题出在什么地方,往往有一种按下葫芦起了瓢的感觉。比如下面的状态图,很难第一时间定位到哪个数据更新导致了 data1 的更新。
如果是单一数据源,那么状态变化就非常清晰。
松耦合,及时模块化
组件之间的交互方式应该是清晰明确的,应该避免你中有我,我中有你的情况。
举个例子加以说明。假如我们有如下交互: 
左侧是商品加购表单信息,表单中间是商品列表。点击添加商品按钮,弹出右侧商品信息选择框,点击确定将商品信息添加到表单中。
在这个交互中,我们的商品信息表单其实是左边表单的子表单。但是,我们不建议在商品信息表单中直接操作左边表单的数据。因为商品信息表单是一个相对独立的模块,它不依赖左侧表单的任何信息。因此,我们只需要给商品信息表单约定一个 value 和 onChange 的接口与左侧表单实现交互即可。商品信息表单内的任何信息变化,都不会直接触发左侧表单信息的变化,而是通过用户点击确定按钮来触发。
辅助代码分离
在组件中,我们通常会有一些计算或者数据转换逻辑。这虽然是组件功能的必要组成部分,但是这样的代码通常会比较长,放在组件逻辑里会打断整体代码的思路。因此,我们需要将这些辅助代码抽取出来,放到相关的 utils 中去。保证主体代码的思路是连贯的。
SOLID 原则
SOLID 原则 是面向对象设计的基本原则,由单一职责原则、开闭原则、里氏替换原则、接口分离原则和依赖倒置原则组成。
在组件开发过程中,我们也应该要借鉴这些原则,来进行组件设计。
 关注微信公众号,获取最新推送~
关注微信公众号,获取最新推送~
 加微信,深入交流~
加微信,深入交流~