
事件驱动架构模式是常见的分布式异步架构模式,通常被用来创建具备高扩展性的应用。其适应性也很强,即可用于小型应用,也可用于大型复杂应用。事件驱动架构由高度解耦、单一用途的事件处理器组成,这些组件异步接收和处理事件。
事件驱动架构模式包含两种拓扑结构:调解器(mediator)拓扑和代理(broker)拓扑。当我们需要通过中央调解器在事件中编排多个步骤时,通常使用调解器拓扑,而当您希望在不使用中央调解器的情况下将事件链接在一起时,则使用代理拓扑。
由于这两种拓扑的架构特征和实现策略不同,我们需要详细了解每种拓扑结构,才能确定在具体的业务场景下,那种拓扑结构更适合我们。
调解器拓扑
调解器拓扑非常适合那些事件具有多个步骤并且需要某种程度的编排来处理事件的场景。
比如,进行股票交易的单个事件可能要求首先验证交易,然后根据各种合规规则检查该股票交易的合规性,将交易分配给经纪人,计算佣金,最后由经纪人进行交易。所有的这些步骤都需要一定的编排,来确定步骤的顺序,以及哪些步骤是可以并行的,哪些步骤是要顺序执行的。
在调解器拓扑中主要有四种类型的组件:事件队列(event queue)、事件调解器(event mediator)、事件通道(event channel)和事件处理器(event processor)。
事件流从客户端向事件队列发送事件开始,事件队列用于将事件传输到事件调解器。事件调解器接收初始事件,之后通过向事件通道发送额外的异步事件来实现编排收到的事件,以执行流程的每个步骤。事件处理器监听事件通道,从事件调解器接收事件并执行特定的业务逻辑来处理事件。
下图展示了调解器拓扑结构。
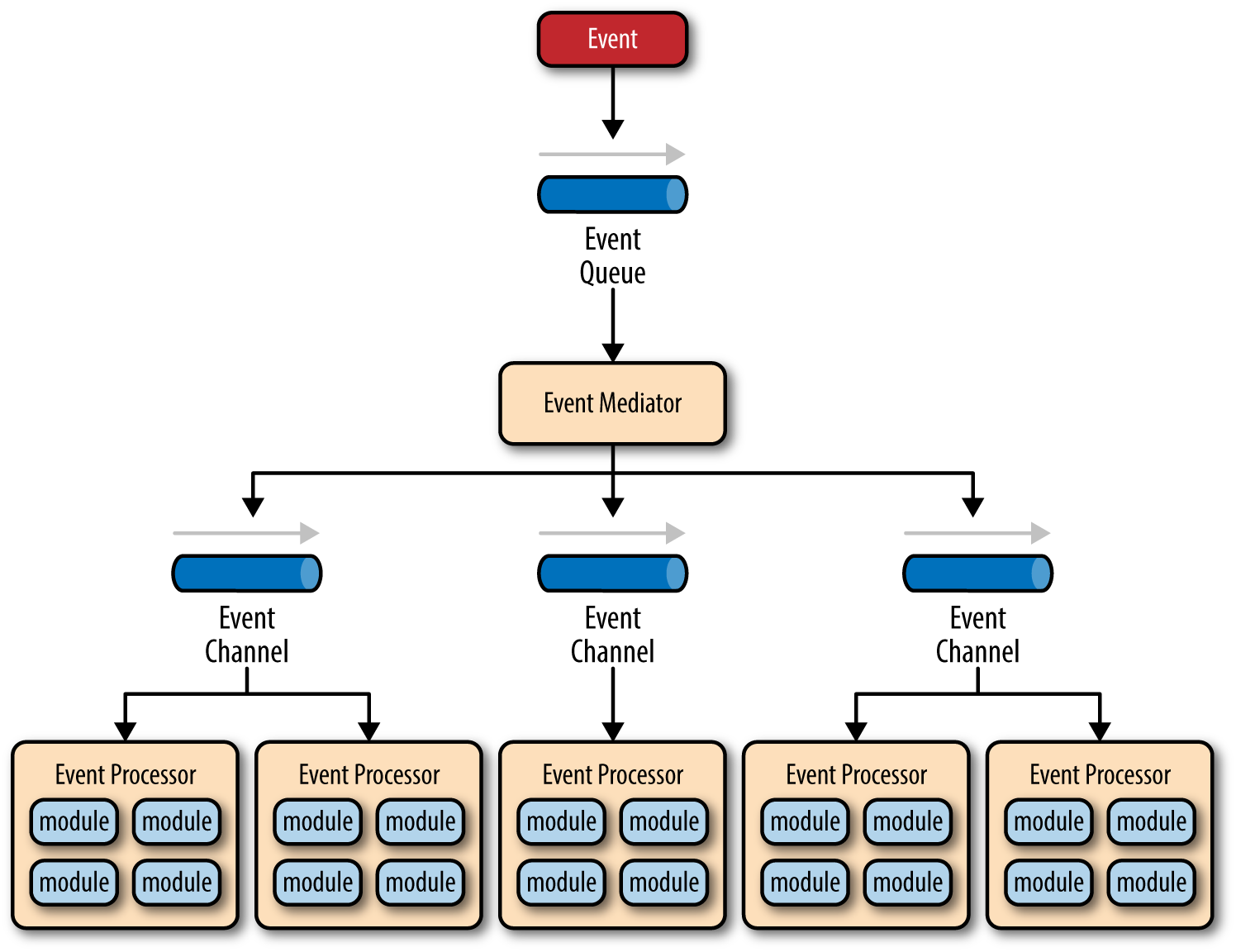
在事件驱动架构模式中,通常有几十到几百个事件队列,并且模式对实现事件队列没有技术要求,可以使用消息队列,也可以使用 web 服务等等。
该模式中的事件有两种类型:初始事件和处理事件。初始事件是调解器接收到的原始事件,而处理事件是由调解器生成并由事件处理器接收的事件。
事件调解器负责编排初始事件中包含的步骤。对于初始事件中的每一步,事件调解器都会将特定的处理事件发送给事件通道,然后由事件处理器接收和处理。需要注意的是,事件调解器实际上并不执行处理初始事件所需的业务逻辑。相反,它知道处理初始事件所需的步骤。
事件调解器使用事件通道将与初始事件中的每个步骤相关的特定处理事件异步传递给事件处理器。事件通道可以是消息队列或消息主题(消息主题使用更加广泛)。处理事件可以由多个事件处理器处理,每个事件处理器根据接收到的处理事件执行不同的任务。
事件处理器是自包含、独立且高度解耦的,它们接收处理事件,然后执行特定任务。事件处理器的粒度可以从细粒度(例如,计算订单的销售税)到粗粒度(例如,处理保险索赔),但是一般来说,每个事件处理器应该执行单个业务任务,而不是依赖其他事件处理器来完成其特定任务。
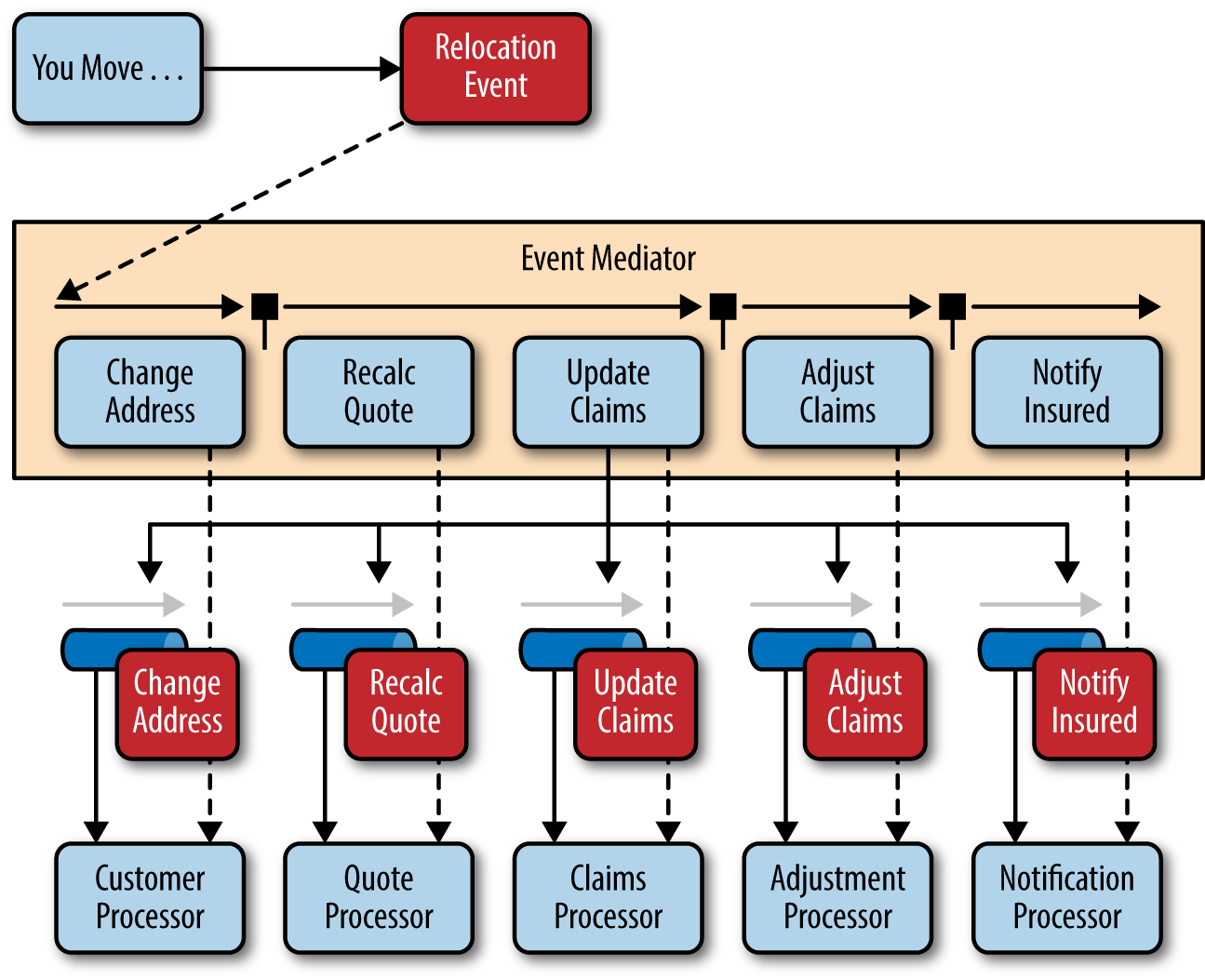
上图展示了在保险公司处理用户搬迁的业务场景中,调解器拓扑是如何工作的。
在这个业务场景中,初始事件叫 relocation event。处理 relocation event 所涉及的步骤包含在事件调解器中。对于每个初始事件步骤,事件调解器会创建一个处理事件(例如,更改地址、重新计算报价等),然后将该处理事件发送到事件通道并等待相应事件处理器处理该处理事件(例如、客户流程、报价流程等)。这个过程一直持续到初始事件中的所有步骤都已处理完毕。事件调解器中重新计算报价和更新声明步骤上方的单条表示这些步骤可以并行运行。
代理拓扑
与调解器拓扑不同的是,代理拓扑没有中央事件调解器。相反,消息流以链式方式分布在事件处理器中。当我们有一个相对简单的事件处理流程并且不想要(或不需要)中央事件编排时,此拓扑结构很有用。
在代理拓扑结构中有两个主要组件:代理器和事件处理器。代理器可以是集中式或联合式的,它包含事件流中使用的所有事件通道。
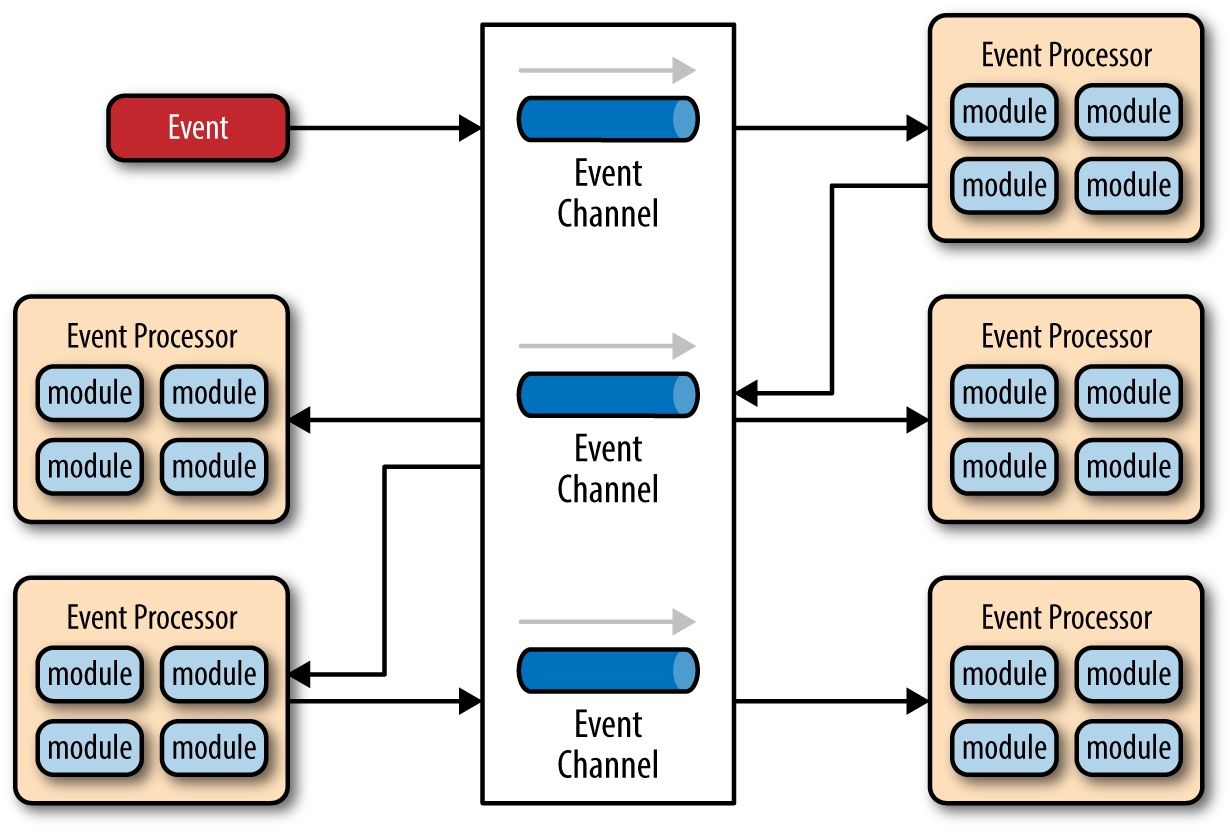
如上图所示,在代理拓扑结构中没有中央事件编排,每个事件处理器负责处理事件并发布一个新事件,这个新的事件表示时间处理器刚刚执行的操作。
我们用调解器拓扑结构中的例子(保险人搬迁)来说明代理拓扑结构。如下图所示。
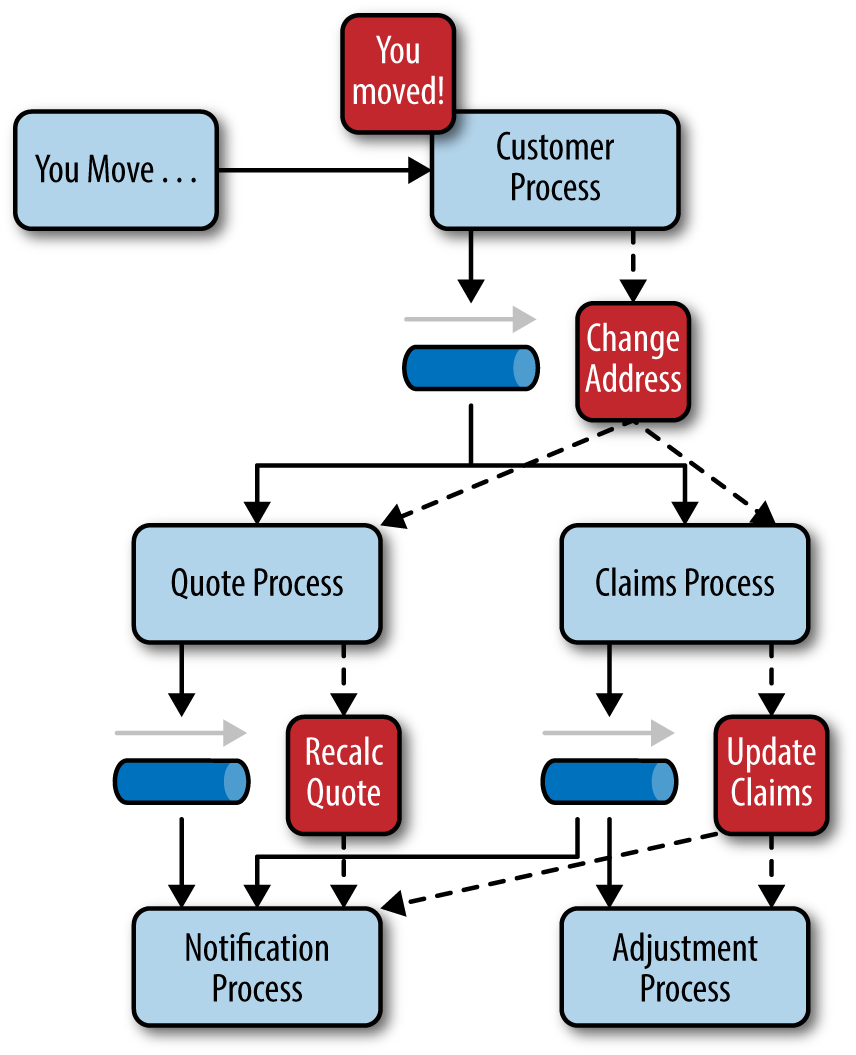
由于在代理拓扑中没有中央事件调解器来接收初始事件,因此 customer process 直接接收事件,更改客户地址,并发送一个事件,说明它更改了客户的地址(例如,change address event)。在上图中,有两个事件处理器对 change address event 感兴趣:报价流程(quote process)和索赔流程(claims process)。报价处理器根据地址更改重新计算新的自动保险费率,并向系统的其余部分发布一个事件,表明它做了什么(例如,recalc quote event)。另一方面,索赔处理器接收相同的更改地址事件,然后更新未完成的保险索赔并发布一个新的事件(例如,update claim event)到系统中。然后这些新事件被其他事件处理器获取,并且事件链条继续在系统中延伸下去,直到没有针对该特定初始事件发布更多的事件。
就像接力赛一样,代理拓扑结构中的每个事件处理器只处理整个事件链条中的一段,整个事件链条串联起了完整的业务逻辑。
其他说明
因为异步并且是分布式的特性,事件驱动架构模式实现起来比较复杂,需要解决各种分布式架构问题,例如远程进程可用性、缺乏响应性以及代理失败时的重新连接等问题。
除此以外,在使用事件驱动架构模式的时候,需要着重考虑的一个问题是,该模式缺少原子事务能力。
因为事件处理器是高度解耦并且是分布式的,我们很难再多个事件处理器间实现原子事务。因此我们需要不停的思考哪些事件是可以原子化执行的,哪些是不能原子化执行的,以此来设计事件处理器的颗粒度。如果我们发现需要通过多个事件处理器来实现一个单元业务逻辑,换句话说我们需要通过多个事件处理器来处理一段不可分割的业务逻辑时,事件驱动模式可能不适合我们当前的业务场景。
在事件驱动架构模式中还有一个问题至关重要,那就是事件处理器之间的通信协议的设计。比如可以是 JSON、XML 等等,在根据实际的业务需要确定好协议形式以后,最好再加上版本控制。
思考
因为事件处理器是高度解耦的,各自之间相互独立,因此可以快速响应变化,同时单个事件处理器的变更不会影响其他事件处理器。
在部署方面,代理拓扑结构比调解器拓扑结构更加易于部署,因为调解器拓扑结构的变更通常要涉及到中间调解器和事件处理器。
因为异步和分布式的特点,事件驱动架构模式通常具有比较好的性能和扩展性。同时也因为这个特点,在开发方面,开发团队需要负责更多的开发成本,比如制定通信协议以及制定必要的错误描述系统等。
 关注微信公众号,获取最新推送~
关注微信公众号,获取最新推送~
 加微信,深入交流~
加微信,深入交流~